Теги: seo факты, seo мифы, исследования
Хотите чтобы мы рассказали ещё о чём-то - предлагайте тему.
Следите за нашими публикациями в социальных сетях и новостных каналах.
Здесь рассказаны факты из занимательного исследования мифов SEO.
Будьте в курсе событий

При выполнении поисковой оптимизации сайта хочется избежать шагов, каких точно делать не нужно. Ну или по крайней мере разбираться, что из типичных советов сегодня безнадёжно устарело, а что с самого начала было фантазией каких-то типов из seo-тусовки. Как раз этому посвящено цитируемое здесь исследование. Вы узнаете очень интересные факты, всё написано простым языком.
Как-то в моей практике наступил месяц исследований: знакомый просил проверить очередное seo-утверждение на достоверность. Даваемые мной отчёты нравились знакомому и его коллегам сеошникам за доказательную базу плюс комментарии по существу. А самые занятные сообщения, отмеченные ими как улётное чтиво, даже ушли в открытый доступ, например доклад о слеше на конце урла - (UPDATE 03.2020 - например доклад о теге H1 одном или нескольких на странице).
С того момента в круг посвящённых запрашивать исследование стали попадать и владельцы сайтов. Однако их интерес концентрировался в плоскости вопроса "правильно ли Вася внедрил нам вот ту seo-правку". Люди просто не доверяли seo-науке, адепты которой совершали непонятные акты. Поэтому расскажу сегодня о результатах, противоположных следующим мифам старой seo-школы (возрастная группа 30+ лет):
В своём отчёте я имею в виду органическую область поисковой выдачи. То есть ту часть результатов, куда страницы попадают естественным образом, а значит бесплатно, и там конкурируют за место согласно неким критериям ранжирования. Поэтому прежде всего владельцам сайтов советую прочесть этот документ, чтобы как минимум успокоить в себе пессимиста: даже молодой сайт может попасть наверх индекса, надо лишь понимать, как тот работает в определённом поисковике.
По ходу рассказа я поверхностно затрону такие ответвления темы:
Рекомендую также молодым сеошникам на время освободить мысли от старинных теорий и понаблюдать за происходящим действом. Поверьте, рассказ окажется увлекательным, и задуматься будет над чем. Я стану выносить в подзаголовок мифический тезис под видом вопроса, а следом отвечать, где нужно прикладывая скриншот. Начну с первого.
Ответ состоит в том, что поисковой системе важнее релевантность публикации, то есть семантическое соответствие поисковому запросу. Если это соответствие достаточно высокое, давность поста уже не имеет решающего значения, он расположится выше любых страниц с меньшей релевантностью, в том числе и новых.
В качестве примера я дал в Гугле низкочастотный информационный запрос "как назначить артикул". На первом месте оказалась страница форума с несколькими комментариями, написанными в один день 2012 года, да в тот же день позабытая, и уж тем более никем никогда нигде не продвигаемая. Однако эта страница так и осталась стоять выше поздних постов других сайтов за 2014 и 2015 годы. Просто потому что с точки зрения поисковой системы была релевантнее. Вот скриншот, на котором я пометил данный факт под номером 1, а заранее отмеченные там же факты 2 и 3 рассмотрю в параграфах ниже:

Конечно, опытный сеошник сообразит, что на позиции результатов поиска может повлиять UX- или региональный факторы. Например, к тому же запросу, выполненному с IP-адресов другой страны, поисковая система в теории способна подобрать уже другие сайты, актуальные для того географического региона. Или скажем, на основании разбора клиентского поведения система вдруг посчитает нужным сменить часть ответов, транслируемых в текущий клиентский сеанс, с целью понять, что клиент таки ищет на самом деле.
Во избежание влияния таких факторов, все скриншоты этого отчёта снимались по состоянию на апрель 2017 года из одной географической точки с предварительным полным сбросом браузера перед каждым снимком. Я не исключаю возможность незаметно вести статистику запросов на стороне поисковика с целью оградить анализатор поведенческих практик от настроек браузера. Скажем, симулировать браузерные сеансовые функции логированием поисковой активности из IP-адреса клиента на протяжении некоторого часа. А значит, изображённые здесь скриншоты вполне могут быть справедливыми лишь в отношении адреса конкретного компьютера. Поэтому к каждому снимку я стану прилагать прямую ссылку на такой же запрос в поисковике, чтобы вы могли повторить этот шаг исследования с вашего компьютера.
Теперь продолжим.
Тогда обратите ещё раз внимание на скриншот выше, а именно отмеченный на нём факт 2. Второе место в поисковой выдаче заняла страница, которая казалось бы лучше отвечает запросу. Ведь аж все 3 слова запроса присутствуют неизменившимися в тайтле результата, вдобавок соблюдают последовательность как употреблены в запросе. Всё же на первом месте стоит другой результат. Потому что алгоритм оценки релевантности сложнее простого поиска точных вхождений.
Сегодня подобный алгоритм - это комплекс машинно-обучаемых функций, измеряющих релевантность формальную, то есть сравнимую по хранимому образу документа, и пертинентную, то есть уместную в плане объёма полезной информации, предполагаемой быть достаточной в ответ на подобный запрос, и вообще всего объёма сведений, сообщаемых документом.
Понятное объяснение пертинентности даёт следующий список ответов на вопрос "чему равно 2х2". Ответы упорядочены по убыванию пертинентности, другими словами, по насыщению информацией, лишней для такой формулировки вопроса:
Подобные новшества поисковых алгоритмов приятны непродвинутым сайтам, ведь облегчают поднятие по вертикали выдачи. Наиболее это заметно в низкочастотных запросах, где влияние прочих факторов ранжирования обычно маленькое, чтобы погасить положительный эффект.
Ну и сеошникам старой школы, разумеется, такие новации не нравятся. Потому что красивый 100% уникальный seo-текст вдруг перестаёт работать по непонятной причине, а на самом деле просто не проходит показатель отношения полезного к общему объёму сведений. Кроме того, нечаянные промашки глагольного смешивания тематик в тайтлах, усложняющие поисковику разбор "о чём же здесь сказано", и другой спам теперь лучше распознаётся как "вода" в документе и при прочих равных условиях с конкурентом за место тянет нарушителя на позицию вниз.

Идём дальше.
На самом деле урл не является предметом семантического, то есть смыслового анализа. Смотрите факт 3 на скриншоте выше. Если рассмотреть всю ссылку страницы первого места, там вообще использован ни о чём не говорящий числовой хеш.
Кстати, некоторые поисковики выделяют участки урла, похожие на слова запроса, но лишь для удобства пользователя. Вот почему поисковые системы умеют читать микроразметку хлебных крошек, если такая присутствует на сайте - чтобы показать урл в результатах поиска более ясным. Не более того.
А старые сеошники почему-то вырастили из визуальной подсветки слов урла миф о какой-то важности букв в адресе страницы. Всё это конечно понятно и где-то даже прощаемо, возраст всё-таки, и кроме того, уровень знаний большинства тех специалистов по большому счёту не дотягивает до современного начального. Зато оставили богатое наследие: мифов наплодили за прошедшее десятилетие в самом деле кучу, ибо сомнительные seo-фирмы сегодня уже легко определяемы по наличию в их аудитах вот таких бестолковых пунктов об урлах.
Развенчаю ещё несколько утверждений. Я обозначил их на следующем скриншоте подпунктами факта 3:

Тот кто стремится написать универсальный текст, покрывающий вариации запросов, должен учитывать наследование множественности вышестоящего семантического узла. Написать такой текст наверняка будет сложно, чтобы притом на вариантах запросов удерживались позиции повыше.
Для примера я просто напишу ту же поисковую фразу во множественном числе, как сразу первые 2 места меняются местами. Смотрите скриншот.

Теперь ссылка на повтор опыта:
Объясняется эффект следующим образом. Всякий несквозной текст страницы проходит семантический анализ. В результате строится некая семантическая модель, представляющая собой иерархию смысловых подчинений элементов друг другу. Так как из сказанного в документе, бывшем на первом месте, следует, что артикул есть иерархический элемент товара, а тайтл вроде бы говорит о единственном товаре, то релевантность документа запросу во множественном числе всё же меньше, чем у документа, бывшего на втором месте. У того как раз артикул тоже есть элемент товара, но тайтл говорит о множестве товаров, следовательно на артикул переносится свойство множественности, и вот тут документ становится целиком релевантен поисковой фразе. Потому передвинут на первое место.
Ответ подобен параграфу про урл: минифицированный html-код, стили, сжатые изображения и тому подобные ускоряющие плюшки не являются предметом семантического анализа. Если документ релевантен запросу, он будет отображён на хорошем месте в индексе даже при слабой вёрстке.
Я просто покажу код той страницы, что оказалась на пьедестале в первом скриншоте. Вот смотрите ниже. Как видите, сделано на уровне "школьник заверстал нам за минуту". Об адаптивности даже и речи нет:

Ссылка на повтор опыта (в браузере Chrome):
Ссылка на повтор опыта в других браузерах (открыть оригинал, выбрать "Просмотр кода"):
Ещё покажу результаты сканирования победившей в поиске страницы с помощью гугловского сервиса проверки на соответствие mobile-friendly (так называемой дружественности к мобильным устройствам) - оценка хуже некуда:

Ссылка на повтор опыта:
Причём примечателен такой момент: старички seo как в отношении mobile-friendly сочиняли ерунду, так и насчёт новой методики вывода результатов в индекс, - её называют mobile-first, - умудрились придумать небылицу, якобы при отсутствии адаптивного дизайна сайт вылетает из поиска.
На самом же деле, если посмотрим, что сказал Гугл 4 ноября 2016 года в блоге для вебмастеров, когда анонсировал начало эксперимента по созданию mobile-first индекса, то прочтём ясное объяснение, что релевантность будет пересчитана в пользу мобильной версии только для сайтов с физически разными версиями вёрстки. Для остальных было сказано вот что:
Последний пункт словно намекает, не увлекайтесь выдуманными страхами. Если на вашем сайте релевантная поисковым запросам информация, отсутствие мобильной версии ничего не значит, ваша подходящая десктопная страница всё равно окажется наверху.
Ошибаетесь. Давайте термином "прокачка" обозначим некое влияние на показатель кликабельности результатов органической выдачи. Такой показатель принято обозначать аббревиатурой CTR - Click-Through Rate. Сейчас нам не интересна природа влияния: было ли оно естественным или каким-то образом накрученным. Важнее веское предположение, что поиск органический и поиск рекламной сети той же поисковой системы основан на единых алгоритмах расчёта.
Таким образом, когда Google вот в этом справочном сообщении "Позиция и рейтинг объявления" перечисляет последовательность факторов, участвующих при формировании рейтинга объявлений в рекламной сети: CTR, релевантность запросу, качество целевого сайта и потом остальные факторы - то мы можем предполагать, что такая же последовательность применяется в органическом поиске.
А значит по массе "непрокачанных" поисковых запросов, то есть в результатах которых нет заметных лидеров по кликабельности, ваши шансы подняться выше известных сайтов достаточно высоки. Ведь там, условно говоря, отброшен первый элемент последовательности, и теперь решающее значение будет иметь следующий фактор - релевантность: правильное написание документа под конкретные ключевые фразы.
А иной раз, просто написав что-то полезное для своих читателей, и даже не помышляя о запросах, ваш сайт вдруг ползёт вверх поискового индекса по такому ключу.
Для примера я задал Гуглу низкочастотный информационный запрос "cms для юридического сайта". На третьем месте оказалась страница знаменитого супермаркета шаблонов TemplateMonster (интересующимся - вот его история). А его сайт всё-таки более известный, чем сайт на втором месте. И тем не менее... в условиях низкой кликабельности страниц по той теме, что связана с поисковым запросом, релевантность в тот момент стала наиболее влиятельным фактором и выше поднялся менее известный сайт, но обладающий более соответствующим текстом.
Этот факт отмечен на скриншоте номером 5. Впрочем, следует понимать, что несколько кликов по какому-то из конкурентов могут очень изменить расклад мест уже на следующем обходе сканирующего робота:

Теперь ссылка на повтор опыта:
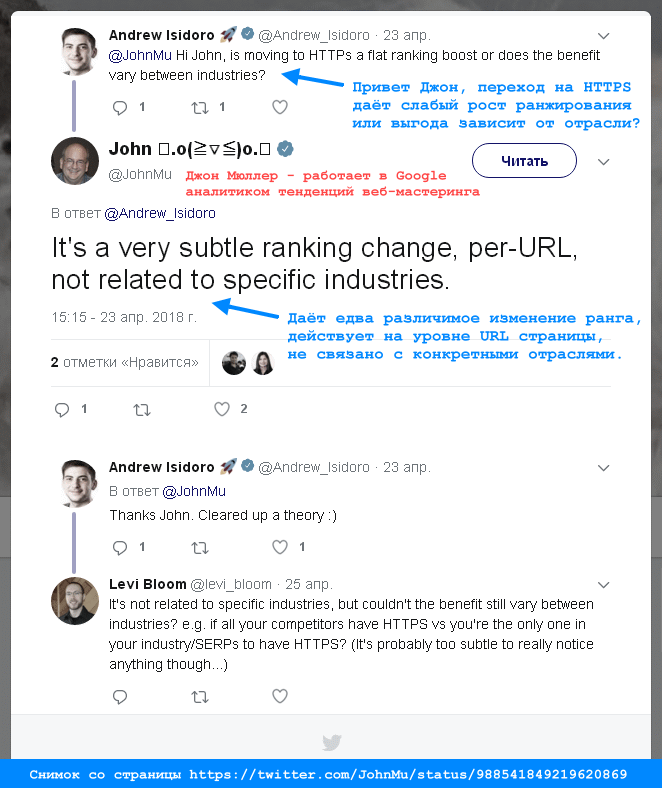
Ещё один факт я отметил номером 5.2, он связан с таким мифом:
Ничего подобного, ведь HTTPS - это всего лишь протокол соединения. Содержимое документа и следуемая из него смысловая модель, удовлетворяющая некоему поисковому запросу, - они ведь не меняются от смены протокола доступа к документу.
Самые желанные быть "осёдланными" среди бизнесменов. Порой кажутся такими неприступными, непонятно по какому принципу выдают ответ. Ведь среди результатов обычно масса сайтов, которые вынужденно используют одно и то же описание товара, списки характеристик и тому подобное. Однако и тут существуют возможности понять выдачу.
Прежде всего необходимо установить, кто ваши более продвинутые конкуренты, а также по каким семантическим моделям поисковая система старается ранжировать их в ситуации, когда из первой поисковой фразы ещё не понять, что же именно хочет найти пользователь. Для решения подобных затруднений поисковики прибегают к записи клиентского опыта поиска, то есть собирают запросы в пакеты "с этой фразой часто ищут". Вот они и представляют собой ту воображаемую семантическую модель запроса.
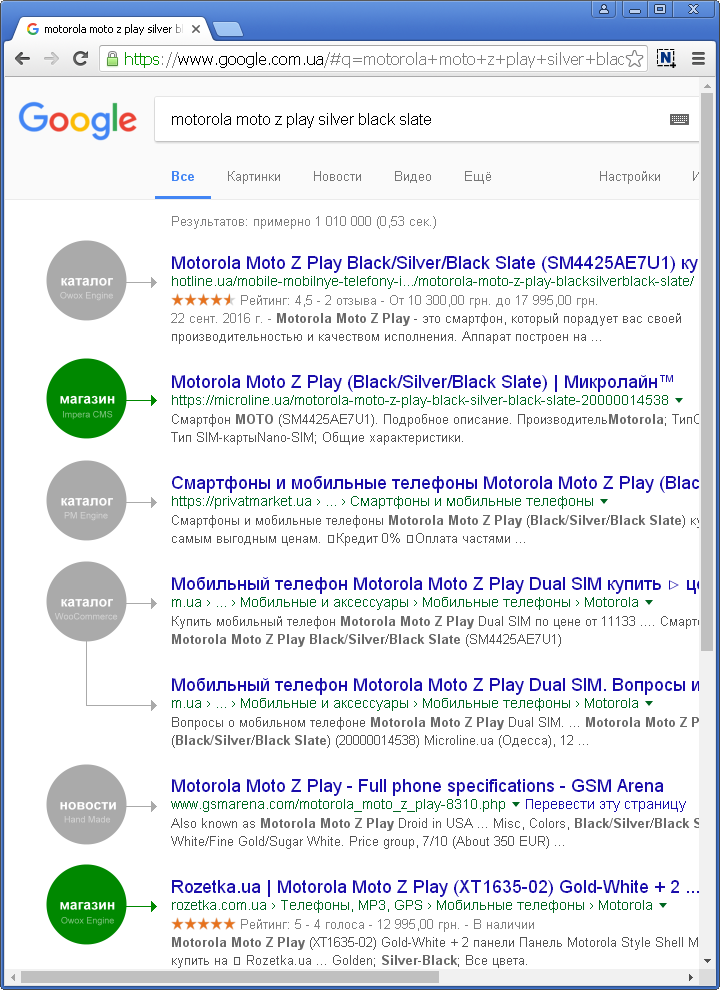
В качестве примера я задал Гуглу некий код производителя ноутбука Lenovo. В ответ нашлось около 70 основных конкурирующих интернет-магазинов относительно географической точки запроса. А под списком выведены поисковые фразы из практики клиентов.
Так вот построив из предложенных фраз общую семантическую модель запроса (смотрите внизу следующего скриншота), можно сделать предположение, что на позиции сайтов в подобных выдачах определённое влияние оказывает наличие покупательских отзывов на странице товара и присутствие там некоторого обзора. Если бы данное предположение каким-то образом подтвердилось, тогда каким слогом нужно писать обзор и отзывы, это придётся устанавливать дополнительным анализом страницы конкурента в ТОПе, чем мог бы и заняться ваш сеошник.

Ссылка на повтор опыта:
Примечателен момент: в результатах подобных нейтральных запросов в течение нескольких суток происходят порой заметные колебания позиций, претендентов снизу переносит на две-три позиции вверх или сносит ещё ниже.
После такой информации логично рассмотреть следующую фантазию древних сеошников.
Разумеется, когда на вас ссылается авторитетный сайт, это хорошо. Но для коммерческих поисковых запросов получить такие ссылки может стоить больших денег. Вдобавок поисковики активно борются со ссылочным спамом, совершенствуя алгоритм ранжирования, постепенно снижая коэффициент при факторе оценки страницы по ссылочному профилю сайта. И значит, вероятность растерять профит от рекламных вложений во входящие ссылки всё время растёт.
Чтобы показать этот эффект в действии, я сделал сравнительную таблицу первых 79 результатов поиска по нейтральной фразе "80SV00B8RA" в Гугле и Яндексе. То есть использовал тот же код ноутбука, в открытую не называя модель. Если поисковики в самом деле предвзяты к ссылочному профилю, то какие-то знаменитые интернет-магазины, имеющие множество ссылок на себя в силу популярности их бренда, напрочь закрепились бы на первых местах обеих частей таблицы. Однако получившиеся позиции результатов поиска, появление там совсем новых имён, в целом подтвердили, что контент играет всё более важную роль в органической выдаче.

Ссылка на повтор опыта (для украинской подсистемы Yandex):
Красным отмечены худшие позиции того же сайта в соседней части таблицы. Зелёным цветом - позиции получше. Прочерк означает, что такой сайт отсутствует в соседней части. Кроме того, зелёным в урле помечены сайты, перешедшие на HTTPS. Как видно по занимаемым местам, этот факт не даёт им какого-то знакового преимущества. А рассмотрение того, как написаны урлы в победивших сайтах, позволило бы ткнуть носом старичков seo в ещё одни их выдумки, которые перечислю уже без пояснений:
Выше была представлена сравнительная таблица поиска из Украины по единой фразе через поисковые подсистемы Google.Россия и Yandex.Украина. Здесь уместен вопрос: насколько меняется выдача через Google.Россия и Google.Украина при поиске из одной географической точки?
Я покажу отличие в следующей таблице сравнения первых 66 ответов на слово "80SV00B8RA". Как видно, результаты почти одинаковые, кроме мест. На украинской подсистеме белорусские и российские домены сдвигаются вниз, пропуская вперёд национальные.

Ссылка на повтор опыта (для украинской подсистемы Google):
Теперь займу ваше внимание небольшим абзацем о том, как поисковые системы по-разному формируют текстовые сниппеты в результатах поиска для тех же сайтов. Следующий скриншот иллюстрирует, сколь трудно написать публикацию таким образом, чтобы поклонники соперничающих поисковиков видели единую текстовку на один и тот же вопрос.

Ссылка на повтор опыта:
Следующий скриншот послужит прекрасным дополнением к проблеме поклонения ссылочной массе. Среди онлайновых магазинов такое поклонение процветает в силу тяжести работы по наполнению сайта собственным контентом, то есть описаниями товаров, обзорами, которые были бы подобны топовым позициям. Речь об эдаком рерайте, да таком чудесном, чтоб отличался в сторону лучшего ранжирования. Для интернет-магазинов подобная практика это нормально. Ну по фактору уникальности текста никак не выделиться перед поисковиком, кроме как переписать описание своими словами. И пусть он сам решает, у кого написано релевантнее с точки зрения семантического анализа.
Однако работа эта по-настоящему тяжёлая. Тут легче поверить в могущество ссылок извне, нещадную внутреннюю перелинковку и прочие seo-ритуалы по замыливанию копипаста, которые в большинстве своём давно уже не работают, потому что поисковики научились признавать массу мусорных ссылок. Всё же в стане сеошников сохраняется большой процент тех, кто слепо верит когда-то выдуманным истинам.
А правда сегодня иная. Для демонстрации я взял урлы 15 первых позиций из прежнего запроса в украинском Яндексе и прогнал через расширенный поиск Гугла, фильтруя в первую колонку только ссылки на победившую страницу, в среднюю колонку - все внешние ссылки на сайт победившего магазина, в третью колонку - внутренние ссылки магазина. Слева в каждой строке измерения обозначил кружками: какое место занимал этот претендент по поисковому запросу "80SV00B8RA" в Яндексе и Гугле. Результаты как минимум свидетельствуют, что число внешних или внутренних ссылок на сайт не всегда ведёт к поднятию его страницы наверх выдачи.

Подсказываю, что значат операторы поиска на скриншоте:
Заметьте В какой-то момент истории поисковой системы Google оператор link:, ранее входивший в публичный список операторов расширенного поиска, был переведён в разряд недокументированных. Это значит отсутствие гарантии, что такой оператор будет поддерживаться в будущем или станет давать точные результаты.
Ещё одна особенность выражается эффектом, что в некоторых ситуациях написания урла или домена результаты поиска выглядят так, будто парсер запроса интерпретировал оператор и его параметр как обычные слова. Как будто вместо link:domain.zone/folder/filename.ext была набрана фраза link domain zone folder filename ext. Тогда количество ответов оказывается завышенным.
Кроме того, следует помнить, что на всю поисковую фразу действует ограничение по количеству обрабатываемых слов. Значит, длинные урлы будут обрезаны, что скорее всего приведёт к неточному списку ответов.
Наверное, нет такого владельца магазина, кто прошёл бы мимо знаний о действиях конкурента. С появлением соцсетей, где разные слои общества стали проводить свободное время, у магазинщиков появился вопрос, сколь много ссылочной массы создают конкуренты в каждой социальной сети. На этот счёт хватает баек, но давайте взглянем на реальные цифры.
Чтобы показать объёмы ссылочных масс в популярных сетях, я снова обратился к нейтральному запросу из предыдущих параграфов. Теперь взял 15 победителей из результатов того же поискового запроса в российском Google и прогнал через фильтр с выделением ссылок на сайт победителя, оставленных только в конкретной социальной сети. Вот что получилось:

Согласно цифрам, топовые магазины не так уж много постят в соцсети. Как правило, туда на обозрение выставляют новые товары, так что видимая часть ассортимента в среднем составляет 2500 позиций. Посты за предшествующие недели, месяцы, годы просто съезжают по ленте вниз, прячутся под аяксовую бесконечную догрузку и ссылки в них более не видны поисковику.
Отрасль разработки сайтов встретила начало прошедшей десятилетки жёстким хардкором шаблонов. Это когда макет от начала и до конца ваял кто-то из умельцев студии - он тебе и каркас проектирует, и программный код стряпает по совместительству, и дизайнит помаленьку, и над seo колдует. В лучшем случае если получался хотя бы не говнокод, то уж трудно поддерживаемая штуковина - это точно.
К середине десятилетки шаблоны сайтов уже рисовали, верстали, кодировали, оптимизировали отдельные обученные мастера. А в характеристиках шаблона вполне заслуженно перечисляли его достоинства: clean code, well documented, seo optimized.
Однако к сегодняшнему дню правила поисковой оптимизации сильно изменились, а понятие "seo optimized" расплылось настолько, что даже опытные покупатели шаблонов стали попадать на минусы поисковой выдачи в результате привычки доверять этикетке "seo optimized" на упаковке очередной модной темы сайта.
Один из недостатков современных шаблонов сайта, это размещение около основного текста страницы всякой вторичной seo-мишуры, которая искусственно уникализируется, чтобы проскочить воображаемый секатор сквозных текстов. Затем на этой проскочившей мишуре осекается воображаемый семантический анализатор, отчего в сниппеты при результатах поиска попадают немотивирующие фрагменты текста.
На следующем скриншоте я покажу пример подобного отрицательного эффекта.

Ссылка на повтор опыта:
Эффект поясняется так. Когда это исследование было опубликовано, Яндекс проиндексировал его в течение суток. И по широкому ключу "факты seo" оно тут же попало на первую страницу поиска, а в качестве двух строк сниппета робот взял два первых тега <p>, которые на самом деле относились к seo-мишуре перед телом публикации. Почему бот поступил именно так - неизвестно.
На второй день бот реиндексировал страницу (это особенность высоконагруженной поисковой индексации: итеративное уточнение семантической модели текста), поднял сайт на 2 места выше по тому же ключу, а строками сниппета выбрал первый тег <p> и первую строку первого комментария. Почему так - неизвестно (UPDATE: Почему - объяснил наш читатель Илья в этом комментарии ниже).
На третий день робот выбрал для сниппета первую строку первого комментария и финальный несквозной тег <p>. Также поднял сайт по результатам поисковой выдачи ещё на 2 места выше. Почему так - неизвестно.
С той поры больше не менялось (UPDATE: Менялось - в следующие дни статья место за местом поднялась на верхнюю строчку). В итоге неброская seo-ошибка шаблона обернулась тем, что сниппет содержит бессмыслицу, текст не побуждающий посетителя заинтересоваться ссылкой.
Привлекательны для бизнеса высокими конверсионными качествами. Ведь набравший их пользователь как правило уже определился, чётко представляет, какой именно товар хочет найти. Поэтому далеко листать не будет, значит конкурентная борьба ведётся за места на первой странице органической выдачи. А притом что у всех почти одинаковое описание товара, характеристики, обзоры, комментарии, то последнему шагу на позицию повыше может помешать банальный недочёт, например в seo-оптимизации шаблона, кривой настройке движка сайта и прочем.
Хоть первая страница поиска обычно содержит самые релевантные сайты, - так сказать на языке сеошников, наиболее оптимизированные под такой запрос, - всё же я покажу, что и здесь могут наблюдаться мелкие шероховатости, выражающиеся в объёме напрасной информации, которую увидит пользователь на странице ответа.
Для примера вместо того кода ноутбука я возьму теперь его полное название, и поищу через Google.Украина. Меня интересуют только первые 10 мест. С целью сравнить, как отличается формирование сниппетов в разных поисковых системах, я повторю тот же поиск через Яндекс.Украина. Результат показан на скриншоте:

Ссылки на повтор опыта:
Чтобы увидеть, оказывают ли влияние на позиции поиска какие-то из факторов, считаемые множеством сеошников будто бы важными (pagespeed, mobile-first, https, микроразметка), я провёл измерение 10 лидирующих ссылок из предыдущего параграфа и собрал отметки в первую таблицу. Смотрите ниже.
Красным цветом выделены совсем плохие показатели, оранжевым - так себе, зелёным - хорошие. В колонке отзывов подсчитано общее число комментариев о таком товаре и рядом серым цветом записано количество отзывов, сообщённых через микроразметку. Красным словом BAD отмечена микроразметка с дефектом, словом WARNING - микроразметка с предупреждениями.
От себя ещё добавил две сводные таблицы замеров по количеству слов поискового запроса, присутствующих в тексте предложенной страницы. В одном случае таблица содержит измерения относительно всего текста страницы, в другом - относительно несквозного текста, то есть той части предложений, что непохожа на текст смежной модели ноутбука, скажем с кодом 80SV00BKRA.
С целью заполнить чем-то лишнюю последнюю колонку я подсчитал там количество перекрёстных ссылок на странице. Колонка перед ней отражает статистику по количеству уникальных слов на странице, а рядом серым цветом записано количество без учёта уникальности.

Первое, что тут же бросается в глаза, у тройки лидеров плохие показатели теста PageSpeed Insights. То есть в принципе сайты из ТОПа не озабочиваются такой ерундой, ибо до сих пор нет доказательных заявлений, что оценки этого сервиса как-то влияют на ранжирование.
Второе - у тройки лидеров всё хорошо с mobile-friendly, покупательскими отзывами и микроразметкой, особенно товарной и рейтинговой.
Третье - на лидирующих страницах равномерное употребление слов поискового запроса в несквозном тексте и низкое отношение общего числа слов к числу уникальных.
Надеюсь, моё исследование сделало какую-то часть шагов поискового продвижения теперь более понятной вам. Владельцам сайтов рекомендую также нанимать сеошников, которые умеют строить хотя бы семантические модели запросов и не "болеют" упоминавшимися выше мифами.
объект SEO > предикат ПРИНАДЛЕЖАТЬ > объект ФАКТ (количество МНОГО)
объект SEO > предикат ПРИНАДЛЕЖАТЬ > объект ФАКТ (количество МНОГО, атрибут МАЛОИЗВЕСТНЫЙ)
МОДЕЛЬ 1 = объект ВЫ > предикат ВЗЯТЬ (атрибут ГДЕ?) > объект МИФ (количество МНОГО)
МОДЕЛЬ 2 = объект Я > предикат СЛЫШАТЬ (атрибут ПЕРВЫЙ РАЗ) > ссылка МОДЕЛЬ 1
МОДЕЛЬ 3 = объект Я > предикат БЫТЬ > объект СЕО (атрибут 9 ЛЕТ)
МОДЕЛЬ 4 = объект ВЫ > предикат НАЗВАТЬ > объект Я (атрибут OLD-SCHOOL)
МОДЕЛЬ 1 = объект ВЫ > предикат ВЗЯТЬ (атрибут ГДЕ?) > объект СЕО (атрибут 9 ЛЕТ) > предикат * > объект МИФ (количество МНОГО)
МОДЕЛЬ 1 = объект ВЫ > предикат ВЗЯТЬ (атрибут ГДЕ?) > объект СЕО (атрибут 9 ЛЕТ) > предикат * (атрибут ПЕРВЫЙ РАЗ) > объект МИФ (количество МНОГО, атрибут НЕЧТО ВОЗРАСТНОЕ)
объект SEO > предикат ПРИНАДЛЕЖАТЬ > объект ФАКТ (количество МНОГО, атрибут МАЛОИЗВЕСТНЫЙ)
объект СЕО (атрибут 9 ЛЕТ) > предикат * (атрибут ПЕРВЫЙ РАЗ) > объект МИФ (количество МНОГО, атрибут НЕЧТО ВОЗРАСТНОЕ)
Теги: seo факты, seo мифы, исследования
Хотите чтобы мы рассказали ещё о чём-то - предлагайте тему.
Следите за нашими публикациями в социальных сетях и новостных каналах.
2. Mobile-first что это поинтерсуйтесь, прежде чем умничать. Индекс для мобильных сайтов.
Mobile-first (сначала-мобильный) - это поисковый индекс с ранжированием сайтов по их мобильным версиям, при отсутствии мобильной - по стационарной версии.